2 ANALISIS DE GENOMAS
La secuenciación total del genoma de organismos se convirtió en realidad en 1995, con la obtención de la primera secuencia completa de una bacteria, H. influenzae. Desde entonces, muchos otros genomas se han añadido a la lista, incluyendo los primeros eucariotas: S. cerevisiae en 1997 y C. elegans en 1999. Los hitos mas importantes han sido marcados en los últimos años por la obtención de los genomas de D. melanogaster (2000), A. thaliana, la primera planta (2000) y, por supuesto, el genoma humano (2001).Los proyectos ya completados han obtenido resultados muy relevantes, que permiten extraer conclusiones no solo sobre la biología del organismo en cuestión, si no también sobre aspecto comparativos de gran importancia para comprender la organización de la vida (¿Cual es el conjunto de genes que son esenciales para crear un organismo viable? ¿Que familias de proteínas son universales y cuales son específicas? ¿Como actua la evolución sobre los genomas?). Es por esto que estos proyectos se han convertido en un referente imprescindible en la biología actual.
El European Bioinformatics Institute (EBI) mantiene una página web (MOT, Genome Monitoring Table), en la que se recoge información sobre el progreso de varios proyectos de secuenciación de genomas eucariotas.
Supongamos que hemos secuenciado un genoma y conocemos ya los genes que contiene, es decir, ya hemos superado la fase de deteccion y modelado de genes.El siguiente paso es anotar el genoma desde el punto de vista funcional, o lo que es lo mismo, intentar predecir la función de cada uno de los genes del genoma y de las proteínas que codifican. Como analizar nuestras secuencias?
La principal fuente de información para el análisis procede de busquedas de homología frente a otras secuencias depositadas en las bases de datos, por ejemplo mediante búsquedas con BLAST. Otro tipo de información también puede ser de importancia: predicciones de estructura secundaria, de regiones transmembrana, presencia de motivos comunes a otras proteinas, etc. Cada herramienta tiene su propio servidor, utiliza un formato propio de los datos de entrada y salida, y en muchos casos no funcionan a traves de Internet, sino que se deben instalar localmente.
Los sistemas de análisis de genomas estan diseñados para eliminar esos problemas: poseen copias locales de las herramientas y bases de datos, y agrupan el acceso a todas ellas, de modo que el usuario simplemente tiene que facilitarles la secuencia o secuencias que quiere analizar. El sistema se encarga de correr todos los programas y dar el formato adecuado a los datos para la presentación al usuario.
Como se puede suponer, los requerimentos de este tipo de sistemas son grandes: gran capacidad de almacenamiento y gran poder de cálculo (muchas secuencias pueden ser analizadas simultaneamente). Por ello, no han sido muchos los sistemas de este tipo que han sido desarrollados para el uso público.
Las páginas web de algunos sistemas de análisis de genomas se presentan mas abajo. De todos ellos, sólo GenQuiz permite a los usuarios el envío de secuencias para analizar.
3 BASES DE DATOS DE
SECUENCIAS E INFORMACION GENÓMICA
Varios grandes centros dedicados a la bioinformática proporcionan acceso las bases de datos públicas dedicadas a facilitar información sobre secuencias genómicas. A continuacion se presentan los enlaces a algunos de ellos:4 COMPARACION DE GENOMASEl Instituto Pasteur mantiene varias bases de datos específicas de ciertas bacterias, que se muestran a continuación. Todas tienen una interfaz gráfica parecida, bien diseñada y fácil de usar. Además de poder extraer información sobre genes y de mostrarla en forma gráfica, se tiene la posibilidad de hacer búsquedas de motivos para, por ejemplo, identificar sitios de unión de proteínas reguladoras (mediante la opcion "Search Pattern").NCBI: Este es un gran conjunto de información biológica que comprende bases de datos de nucleótidos (GenBank), de proteinas, de informacion bibliografica (Medline) y tambien genomas. Este servidor contiene las secuencias de todos los genomas virales completados. Para acceder a la seccion de genomas, entrar primero en Entrez y, después, seleccionar Genome. TIGR Databases: El instituto que llevó a cabo la secuenciación de los primeros genomas, posee un catálogo de los genomas secuenciados con enlaces a los análisis de cada uno de ellos. Completed genomes at EBI: sitio del European Bioinformatics Institute. The Wellcome Trust Sanger Institute, que, como TIGR, ha participado activamente en la secuenciación de muchos genomas. Ensembl, genomas eucariotas SGD, Saccharomyces Genome Database, levadura.
Subtilist,Bacillus subtilis. Colibri, Escherichia coli Tuberculist, Mycobacterium tuberculosis MypuList, Mycoplasma pulmonis Leproma, Mycobacterium leprae
Un nuevo y muy importante aspecto del análisis de genomas se encuentra en los estudios comparativos entre distintos organismos. Hasta hace pocos años estos tipo de análisis eran muy dificiles de realizar, por la inexistencia de genomas completamente secuenciados, que hacia que las comparaciones a menudo fuesen incompletas.Así como las herramientas que hemos visto hasta ahora iban principalmente encaminadas a predecir la función de nuestras secuencias, las comparaciones nos ofrecen informaciones adicionales: pertenencia a familias conocidas, perfil filogenético (presencia en otros organismos), pertenencia a operones o clusters de genes (genes que se presentan agrupados en diferentes organismos, lo que a menudo tiene implicaciones funcionales), etc. La información comparativa puede incluso ayudarnos a predecir la función para ORFs de funcion desconocida en el organismo que analizamos: comparando diversos organismos podemos conocer aquellos genes/proteínas que realicen funciones esenciales y que no hayan sido descubiertas en este. Las bases de datos de metabolismo son de considerable ayuda en este punto. La información posicional tambien es muy importante: la función de algunos ORFs puede conocerse de acuerdo a su vecindad con ORFs de función conocida, si esta disposición esta conservada en diferentes organismos.
Algunas bases de datos especialmente orientadas al estudio comparativo de genomas son:
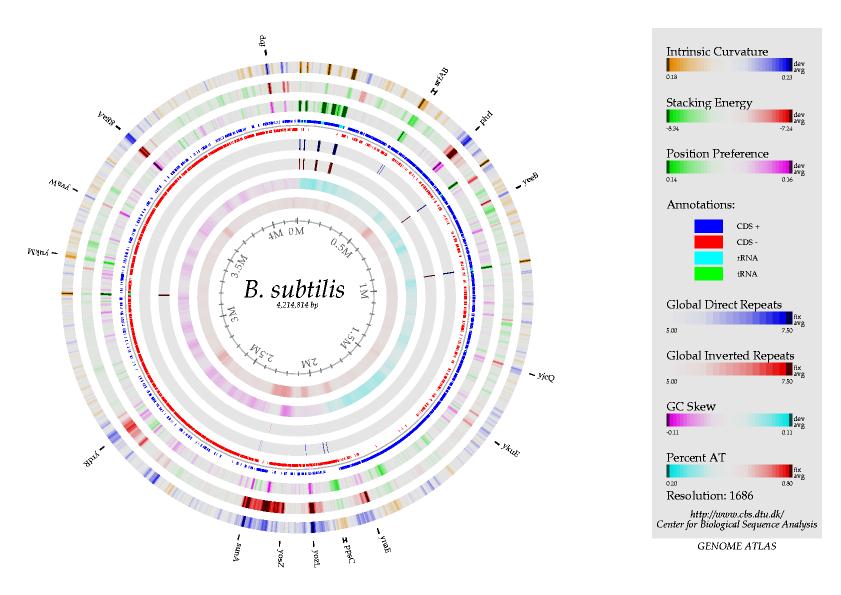
COGs. Esta base de datos del NCBI consiste en unas 2800 familias de proteinas conservadas o COGs, que contienen grupos de proteínas ortólogas. Por definición, dos proteínas, o genes, son ortólogos si han evolucionado a partir de un mismo ancestro. Tipicamente, genes o proteinas ortólogas tienen la misma función; no tiene por que ocurrir lo mismo entre genes o proteínas parálogas, que en vez de haber sido originadas por especiación (divergencia entre especies), han sido originadas por duplicación de un gen y posterior evolución hasta, a veces, desarrollar una nueva funcionalidad. Dado que cada COG incluye proteinas de organismos filogenéticamente muy diversos, este sitio es especialmente útil para asignar función a proteínas que no muestran un grado significativo de similaridad con otras proteínas. Para ello, el usuario tiene la posibilidad de enviar secuencias a traves del interfaz COGnitor, que serán analizadas y asignadas a alguno de los COGs existentes. Otras herramientas disponibles en COGs permiten analizar la distribución de genes en genomas (Phylogenetic patterns) o analizar semejanzas entre genomas mediante análisis de componentes principales. KEGG. Esta es la Kyoto Enciclopedia of Genes and Genomes, y está centrada fundamentalmente en la comparación de genomas en cuanto a su capacidad para codificar diferentes rutas metabólicas. El usuario puede obtener mapas metabólicos e identificar qué enzimas están presuntamente codificadas por un genoma en concreto. Otro tipo de análisis posible con KEGG es la identificación de clusteres de genes (o grupos de genes consecutivos) conservados entre dos especies. MBGD. La Microbial Genome Database es otro sitio muy util para identificar genes o proteinas homólogas, en varios genomas. PEDANT es un sistema para análisis de genomas. Aunque no es accesible desde el exterior (no podemos analizar nuestras secuencias), si podemos examinar los análisis ya realizados para gran cantidad de organismos, incluso algunos aun no completos. DNA Structural Atlas. En esta pagina web se recoge el análisis estructural de muchos de los genomas procarioticos secuenciados. Es posible acceder a una serie de datos estadísticos (contenido A+T, densidad de genes, etc) y a una serie de atlas o mapas circulares en los que se representa la medida de muchos parámetros (curvatura, secuencias repetidas, palíndromes, etc), como el que se ve en la figura siguiente.
![]()