|
Práctica Eucariotas
|
|
Vamos a analizar con diferentes herramientas de prediccion de genes
una secuencia del genoma humano y una de A.thaliana. Intentaremos ver donde están los exones
y los intrones, si hay una región promotora en la secuencia y decidiremos de entre todas
las estructuras génicas propuestas por las diferentes aplicaciones, cual nos
parece mejor. |
|
Sequencia 1:
|
Sequencia 2:
|
>human
AGCTTTCTTCTTTTCCCTGTTGCTCAAATAAATAGTGTTCTTTGCTCAAA
CCCCCTTTCCCTCCTCCTTCTGCAATCTCAGCGCCTAGCGAAATCTGTTT
TCTTCATTGTAACCTCAGCTTCACCGCAATTAATTTTTTTTCCCTCTGGT
CACAAGATAATTCCTGACGCCAGTGAGTCTGGAGGTCAGACGAACAGCAA
ATTGGGGAACAAGGCGGCACTAATTCCTTACAAGTTCCTTGAAAAATCTT
TCGCTTAAAAAAAACGGGGGGTGGGGGGAGCTTCTTTGCTGTTCAGGGAT
TTATGCCTCGCGGAGCTGTGGCTCGAACCAGTGTTGGCTAAGGCGGACTG
GCAGGGGCAGGGAAGCTCAAAGATCTGGGGTGCTGCCAGGAAAAAGCAAA
TTCTGGAAGTTAATGGTTTTGAGTGATTTTTAAATCCTTGCTGGCGGAGA
GGCCCGCCTCTCCCCGGTATCAGCGCTTCCTCATTCTTTGAATCCGCGGC
TCCGCGGTCTTCGGCGTCAGACCAGCCGGAGGAAGCCTGTTTGCAATTTA
AGCGGGCTGTGAACGCCCAGGGCCGGCGGGGGCAGGGCCGAGGCGGGCCA
TTTTGAATAAAGAGGCGTGCCTTCCAGGCAGGCTCTATAAGTGACCGCCG
CGGCGAGCGTGCGCGCGTTGCAGGTCACTGTAGCGGACTTCTTTTGGTTT
TCTTTCTCTTTGGGGCACCTCTGGACTCACTCCCCAGCATGAAGGCGCTG
AGCCCGGTGCGCGGCTGCTACGAGGCGGTGTGCTGCCTGTCGGAACGCAG
TCTGGCCATCGCCCGGGGCCGAGGGAAGGGCCCGGCAGCTGAGGAGCCGC
TGAGCTTGCTGGACGACATGAACCACTGCTACTCCCGCCTGCGGGAACTG
GTACCCGGAGTCCCGAGAGGCACTCAGCTTAGCCAGGTGGAAATCCTACA
GCGCGTCATCGACTACATTCTCGACCTGCAGGTAGTCCTGGCCGAGCCAG
CCCCTGGACCCCCTGATGGCCCCCACCTTCCCATCCAGGTAAGCCTCGAA
GTCGGGACAGGGCTGAACACCCAGGCAAGGATGCTGCGGGACCCTCGGAG
CTCCCGATTGCCTCGCGTAACTCTTCCCTCTTTTCCTCTAATCAGACAGC
CGAGCTCGCTCCGGAACTTGTCATCTCCAACGACAAAAGGAGCTTTTGCC
ACTGACTCGGCCGTGTCCTGACACCTCCAGGTGAGTATCTCCTCTCTTGG
AGAGGGAGGTTTAAACGGCAAGTCCTGGAGTTGGCAGACGTTTTGAAAAA
TTGCCACTCACTCGGTTTAGGGAAACTGAGGCCAGAGAGGGACAAGTGAC
TTGCCCATGGTTGCATCAAATGAATGGCAGAGTCAGTTTCCATGTGATGT
GCATTTAAGCCTTAATGCGCCTGGCCCTGCCTCCGCAGTGGCCGAGGTCT
GGCAAGTAGACATGGTCCGACTAAATACAAGTCTTTCTGTTCCATGTTGT
ATAGGAGCTGTCTTCGGCAGCCCCCTCCCAGCTAGTGTCAATTCCAAGTA
GGAGGGGTAGCGCAACGTCCGCCTGTGGTCTTTGGCGCCAACTGGGTGGG
GGCAGCGTGGGGGGCGGAGTTATCAGGCTGGAGGTACAGACCAAGTTTCC
TCCCTGGCGCCGGCCAGTCTGCGGACGGCCCCCGCCTCGGCACGCTCGGC
GGAAACTGACTGCTCCTTGGTCTTCTTTCCTCCCCCGCCCAGAACGCAGG
TGCTGGCGCCCGTTCTGCCTGGGACCCCGGGAACCTCTCCTGCCGGAAGC
CGGACGGCAGGGATGGGCCCCAACTTCGCCCTGCCCACTTGACTTCACCA
AATCCCTTCCTGGAGACTAAACCTGGTGCTCAGGAGCGAAGGACTGTGAA
CTTGTGGCCTGAAGAGCCAGAGCTAGCTCTGGCCACCAGCTGGGCGACGT
CACCCTGCTCCCACCCCACCCCCAAGTTCTAAGGTCTTTTCAGAGCGTGG
AGGTGTGGAAGGAGTGGCTGCTCTCCAAACTATGCCAAGGCGGCGGCAGA
GCTGGTCTTCTGGTCTCCTTGGAGAAAGGTTCTGTTGCCCTGATTTATGA
ACTCTATAATAGAGTATATAGGTTTTGTACCTTTTTTACAGGAAGGTGAC
TTTCTGTAACAATGCGATGTATATTAAACTTTTTATAAAAGTTAACATTT
TGCATAATAAACGATTTTTAAACACTTGTGTATATGATGACACCCGTCTC
CATTAAGTACTAATGATGCTTTCTCGCACATGGCCGAATTTTGGGAGCTT
TGGGAAAGTGAACTTGCTTATTCTACGAGAGGGAAATGAAAAACTGCCTG
GTTGAGAGGGGATGGGGTGGAGAGAGAAGGGTTCATGATGGGAGTCTCAT
GTCCATTGAGGGATGGGTGCAGAGAAAAGTTCTGGCTCTGCCTCATTATT
TCAGAGATGAAACCAGAGACTGGTGCAAGCT
|
>Arabidopsis
GCCATATTGC TTTCCTCTTT AGCCAAATTG CGTGTTAATA TCCTTCCCGT
TGCATTTGAT TCTATATCTT GTTTCTGTTT GATTTTTATG CATCTGTCAC
CTCCATGATA GTTTCTCTTG GTTAATGGCT GAAACAAGTT TAGTTTTGGA
TAGAGAATCA AAGAGTCTCT TCTTGTTCGT TTGTATCTTT CCTCTTGCGG
TATATGTTGA AGAACTTTAG GGAAACAAAG TGAATGAAAG CTAAGAGTTT
TTTTTATGAC CAAAGGCAAA ACAAAAAGTG AAGAATATTC CTTTGGAAAG
TTTTGAAAGG GAAATACATA TAGGATATTA ACTAGGCGAA TGGAATTTTT
TCACTCATAC AGAGTCATTT TCTGTATATA TAACTTAGTG ATTGTGAGTT
CTCATATTGC TTCTATGTAA CACTCCTTGT AAAGCTAAAT AGCCCTTTTG
TGCTAAGTCT CTGATATCTA TTGTTATCTT CTCAATACTG CACTTGTTCA
ATGACACTTG CTAGCGATTT TGGTTTTCCA TCCGCTATAT CTTCATCTTT
TACAATTCTA GAAGAGAGAT ACCACAATAA CTTTCCTAAC ACTTTGTGTG
TTTCATCAGG ACAGGAATCG ATGAATAACA ACCCCGTCCC CTGTCAGGTG
TTTCCTCTGG TCTCTGGTGG TAGTTCTGGT GGGAATTTGT TTTCATCTTC
TTCCGGATTC TGCAATGGTG TCTATGTTTC ATCTTCCTCC CAGGCACGGC
CATCTGTTTC TACCGTGCCA AGAGACAGAA TTACTGTTGC TCACGTCTCT
GGTGAAGGGC AGAGGCAGGA ATGCCCTGTG GAAACACATT CCTTGCAATT
GATCAATCAA CCTCAAGAAC AGAAAATTAT GACTTGGTCT TCAGACCAGA
TTCGGGGCTT CTTCGATTTT CCTGTTCCAG ATCCACAAGC AGCGAGCAGC
AGAACTATGG TTTCATCCAA GGAAGTGCTT TCAAAATGCG AATGGCCAGA
CTGGGCGGAT CAGTTGATCT CTGATGATAG TCTTGAACCA AATTGGTCGG
AGCTTCTAGG TGATCCTAAT GTACTCAATC TATATTCAAA GGTTCGTTTC
TTTCAGCTAA ATATGAATCT CTACGCTTAT TTCAGCTAAA TATGATTCTT
CTATTAAGAC TGACTCTGAT AATGTCTTAC AGATAGAAAC ACAGTCTTCT
GATATAGCAA GGCAAGAGAT CGTCTTTAGA AATCAGCATC AGGTGGATCC
ATCAATGGAG CCGTTTAATG CCAAAAGCCC ACCAGCTAGT TCAATGACAT
CTAAGCAAAG AATGCGTTGG ACACCAGAAC TTCATGAAGC ATTTGTCGAA
GCTATCAATC AGCTCGGTGG TAGTGAACGT GCGTATGCCC TTTTTTTTTC
CTTCTCATGC CTGCAAAATT TAGCTGAACA ACTTATTATT ATTCTCTTGG
CTTATAATTT CAAACCACAG GAGCCACCCC TAAGGCTGTT TTGAAGCTCA
TCAATAGCCC TGGGTTGACC GTTTATCATG TCAAAAGCCA TTTGCAGGTT
ACTATTCTCC ATCTATGTTT TCGGTTTGTA TGCTTACAGC TCATCTTAAA
CGTCTTTATA TTATTGGCTT GTCCAGAAAT ACAGAACTGC AAGGTATAAA
CCAGAGCTTT CCAAAGATAC AGGTACTTGA GGCATCTAAG GATTCAAACT
GTCTTCTCAA TATTTCACAT AAGCTTATTA TACTTTGGAA ACATAATGGC
ATTTAAAAGA CTCTTGTGTG ATGAAACACG TCTTTATACA TAATCAGCTT
TTCTTCTTGG ACAGAAGAAC CTCTAGTAAA GAATTTGAAA ACCATTGAAG
ATATCAAATC TCTTGACTTG AAGACGTAAG GAACATTTTA CTTCTCTGTC
AGAACAGACT AAGTATCACC TAGGATAATA TTTCTTCATA TCTAAGATTT
TTTTTTTTTA TTCTTCTTCA GGAGCATTGA AATCACTGAA GCTCTCCGGT
TACAGATGAA AGTTCAAAAA CAACTCCACG AGCAACTTGA GGTATAATAA
TTCAAACTGC CTAAAAGAAG CTTTTATAAA ACAAAACAGT GTCCTTTCCT
CTTCATTTGT CTGATTTCTT AGTTTTTGGT TTTAGCTGGT GATTTTGATC
TTATATTGGT CTTAATACAA TGCAGATCCA AAGATCACTG CAGTTACAAA
TCGAAGAACA AGGTCGGTAT CTTCAGATGA TGATTGAGAA ACAACAGAAG
ATGCAAGAGA ACAAAAAAGA CTCTACTTCC TCATCATCAA TGCCAGAAGC
TGACCCTTCA GCTCCATCAC CAAACCTTTC ACAACCTTTC CTCCATAAAG
CAACCAATTC AGAACCATCA ATAACTCAGA AACTGCAGAA TGGTTCTAGC
ACAATGGATC AAAGTGAATC TACTTCTGGG ACTAGTAATA GAAAACGGGT
TAGAGAAGAT TAGACATCTC ATGAGTATGA TCCAAAGATG TTGCAAACAT
ATGTAATTGT GTATATAAAA TTGAAAATAT CACAGCAGCA AGAAAATGAA
AATTTCTTCT TAATGGAGAT GACGTGGACA AATCACTGTC GAGTTGGAAT
GTTGTCGGCT GATGAGTCAG CAATTTAGAT GACGTGGCTA AAGAACATCC
TTATTTATGA CGTAATTAAT AATGATCTCT CGAAATGCGT CTTTTCTTCG
TCTGTTCTAT CTTCTTTACC AATTTCTGCA ATTCTGGAGA AGCTAAAGGT
CTCAATCTCT CAGTCAAAAA CAAAAGGTCT CTCCTTTATT AAACTATCTA
TCACTAACTA GAAGAAGAGA TTAGAGGAGG AGGAAGAAGA TGTTGTTTCA
GGTGGGAGGT GAAGGCACAC GCCCCACCTT CTTTGAGATG GCTGCTGCTC
AGCAACTTCC TGCTAGCCTT CGCGCCGCTC TCACCTATTC CCTCGGCGTA
TAATGCCCTT CTC |
|
Pasos:
|
|
Existen varios servidores de predicción de genes. Cada uno de ellos basa la busqueda
en propiedades o algoritmos diferentes generando en ocasiones resultados distintos.
En general es conveniente consultar a varios de ellos para tener una idea clara de
la estructura génica de la secuencia.
|
- Vemos si hay evidencias de transcripción de algún fragmento de nuestra secuencia. Para ello
usaremos la herramienta de BLAST contra una base de datos de EST (expresed sequence tag). Generalmente son fragmentos pequeńos
de genes. En esta búsqueda nos interesará el mejor alineamiento posible de la sequencia de EST
con nuestra secuencia del gen. Lo ideal es encontrar un EST que alinee con nuestro gen
con un valor de e-value muy muy bajo.
- Entramos en la pagina web del Blast del NCBI
y pinchamos en "Standard nucleotide-nucleotide BLAST [blastn]
- Copiamos nuestra secuencia y la pegamos en la caja de "search"
- Elegimos la base de datos de "est" en el apartado "Choose database". En el caso de la secuencia de humano,
elegimos la de ESTs de humanos
- El resto se deja como está y pulsamos "BLAST!"
Después de un rato debería salir un resultado semejante a este
|
- Vemos si hay evidencias de transcripción de algún fragmento de nuestra secuencia.
Seguimos los mismos pasos que los descritos para la secuencia humana, aunque en éste caso la base de datos seleccionada
debe ser "est" o "est-others". Después de un rato debería salir un resultado semejante a este
|
żQué podemos deducir de este resultado?
żQué significan, en el gráfico, las líneas negras discontinuas que vemos entre las lineas rojas?
żSería suficiente con este resultado para conocer la estructura génica de nuestra secuencia?
|
- El número de ESTs producidos en estos últimos ańos ha sido enorme y en algunos casos podrían cubrir el genoma entero.
Aunque podamos haber solucionado nuestro problema con un simple blast contra EST, hacemos trabajar a los siguientes servidores
para que nos den su visión de la disposición de los exones, intrones y promotores.
|
- Hacemos trabajar a algún otro servidor
para que nos den su visión de la disposición de los exones, intrones y promotores.
|
Con estos resultados, żpodemos hacernos una idea de dónde están mis exones en la sequencia?
Para esto lo mejor es coger una hoja e ir dibujando de forma orientativa la localización de los exones por cada programa.
żHay diferencias entre lo que nos indica el alineamiento con EST y lo que nos dan los diferentes programas?
żHay diferencias entre los programas?
|
- Usaremos Proscan para buscar posibles promotores.
żHay algún promotor interesante?
results.
|
- Usaremos Proscan para buscar posibles promotores.
żHay algún promotor interesante?
results.
|
- Ahora vamos a repetir el proceso en un metaserver. Los metaservers son servidores que utilizan varias aplicaciones sobre la secuencia que le demos.
En algunos casos devuelven los resultados de todos los servidores a los que han consultado y en otros integran las respuestas en un único resultado.
Vamos a METAGENE
- Escribimos nuestro correo electrónico en el campo correspondiente. No es obligatorio pero si conveniente
- Insertamos la secuencia en "Sequence"
- Pasamos a Sequence analysis options
- Orientation y Fetures: todo seleccionado
- Engine Select: todo seleccionado
- Ebest: Human y Both seleccionados
- GeneFinder: FGENE y Human seleccionado
- GeneID: Human seleccionado
- GeneMark: H.sapiens W size 96 Threshold 0.5 ORFs y Regions seleccionado
- Genei: Human or other seleccionado
- GeneScan: Vertebrate seleccionado
- Genview: Human seleccionado
- Grail: Human seleccionado
- Nnpp: Eukaryote seleccionado
- ProScan: ---
- Submit
Para ver los resultados hacemos click en el enlace "Current Search Results". Esto nos llevará a una página donde tendremos
la oportunidad de ver el resultado de cada servidor en detalle. Lo más conveniente es apretar donde pone "click here to annotate the results"
Esto nos abre una ventana donde compara los resultado de todos los servidores. En el menu pinchamos en tools
y seleccionamos analysis
y luego statistics.
żVemos algo nuevo?
Fijarse en lo que dice Ebest.
Nota: GeneBuilder también es una herramienta muy compoleta de análisis.
No consulta a varios predictores de genes pero si busca ESTs y tiene un entorno gráfico
con mucha información. Es sencillo e intuitivo, prueba a usarlo con este ejemplo en el día de la práctica libre.
|
- Metaserver
Vamos a METAGENE
- Escribimos nuestro correo electrónico en el campo correspondiente. No es obligatorio pero si conveniente
- Insertamos la secuencia en "Secuence"
- Pasamos a Sequence analysis options
- Orientation y Fetures: todo seleccionado
- Engine Select: quitamos geneID y geneview
- Ebest: Others y Both seleccionados
- GeneFinder: FGENE y Plant seleccionado
- GeneMark: A.thaliana W size 96 Threshold 0.5 ORFs y Regions seleccionado
- Genei: Human or other seleccionado
- GeneScan: Arabidopsis seleccionado
- Grail: Arabidopsis seleccionado
- Nnpp: Eukaryote seleccionado
- ProScan: ---
- Submit
Para ver los resultados hacemos click en el enlace "Current Search Results". Esto nos llevará a una página donde tendremos
la oportunidad de ver el resultado de cada servidor en detalle. Lo mas conveniente es apretar donde pone "click here to annotate the results"
Esto nos abre un ventana donde compara los resultado de todos los servidores. En el menu pinchamos en tools
y seleccionamos analysis
żVemos algo interesante?
|
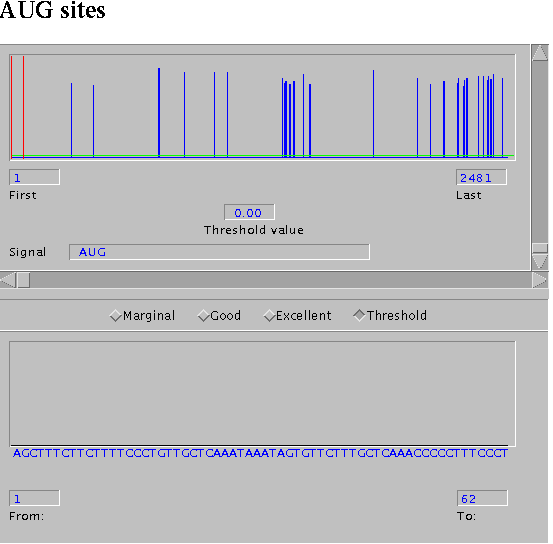
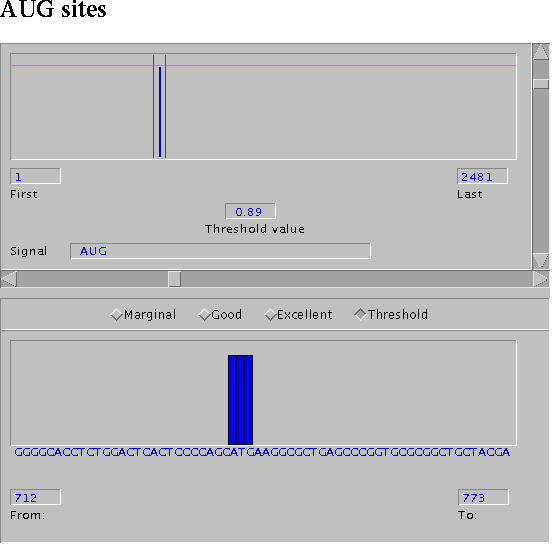
- Otras cosillas que podemos mirar en la secuencia son los posibles codones de iniciación.
AUG evaluator.
Simplemente elegimos la especie e insertamos la secuencia en el campo correspondiente. (res)
żHay algún codon de iniciación excelente? (res)
żDónde está el mejor codon de iniciación y a que valor de threshold lo encontramos? (res)
żConcuerda con nuestro análisis?
- Yá lo último: żSe puede detectar alguna isla GpC que coincida con el principio del gen?
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}