In this practical lesson we will go through several examples to illustrate the concepts of "PATTERNS", "PROFILES", "MOTIFS", "DOMAINS" and "FAMILIES". Each of the exercises will be centered in the analysis of a specific sequence, as it is described later.
The examples include results from database searches or from the application of several tools.
HOWEVER, the idea is that you should repeat by yourself the various analyses that are mentioned.
A selection of links to Databases and Tools:
General Tools: Pattern Tools and Databases:
- PROSITE: Database of protein motifs expressed as patterns or profiles
- ScanProsite (several mirrors): Scans a sequence against PROSITE or a pattern against SWISS-PROT and TrEMBL
Profile Tools and Databases:
- PRATT: Generation of patterns (regular expressions) from a group of unaligned sequences.
- NCBI PSI-BLAST: Automatic generation of profiles in iterative searches.
- ProfileScan: Scans a sequence to find matches to protein patterns and profiles in PROSITE and Pfam.
- MOTIF: Scans sequences to find motifs; databases to find sequences that match profiles or patterns; and generates profiles from sequences provided by the user.
- InterPro: Database of protein families defined by presence of common motifs and domains, defined in several databases such as Pfam, SMART, Prosite, and other.
- Pfam: database of protein HMM profiles that define domain families.
- Sanger Institute (UK)
- St. Louis (USA)
- Karolinska Institutet (Sweden)
- Institut National de la Recherche Agronomique (France)
- Bioaccelerator: allows the generation of profiles and the performance of several kinds of searches. .
- Meme: identifies conserved motifs in groups of sequences, and generates profiles that can be used to search related sequences.
RPE_YEAST, from Saccharomyces cerevisiae, annotated as: "Ribulose-phosphate 3-epimerase".
>my_protein
MVKPIIAPSI LASDFANLGC ECHKVINAGA DWLHIDVMDG HFVPNITLGQ PIVTSLRRSV
PRPGDASNTE KKPTAFFDCH MMVENPEKWV DDFAKCGADQ FTFHYEATQD PLHLVKLIKS
KGIKAACAIK PGTSVDVLFE LAPHLDMALV MTVEPGFGGQ KFMEDMMPKV ETLRAKFPHL
NIQVDGGLGK ETIPKAAKAG ANVIVAGTSV FTAADPHDVI SFMKEEVSKE LRSRDLLD
The blocks of positions (2 to 11) and (25 to 53) are clearly more conserved than the rest of aligned segments, and therefore, correspond to PROTEIN MOTIFS that could be characteristic of the RPE protein family. As you know, protein Motifs can be efficiently represented as simple patterns or regular expressions, if they correspond to sequences that are not too long. Therefore, we will now produce regular expressions that represent some of these Motifs, and we will try to find other sequences that also contain them.
You have now TWO options: you can generate MANUALLY your own pattern, or use some AUTOMATIC algorithm to do it.
Best Patterns (after refinement phase):
fitness hits(seqs) Pattern
A 1: 23.2043 16(
16) H-x-D-[IMV]-x-D-x(4,5)-N-x-[ASTV]-[FILMV]
B 2: 19.0342 16(
16) D-[IMV]-x-D-x(4,5)-N-x-[ASTV]-[FILMV]
C 3: 16.7715 18(
16) D-x(2,4)-H-x-[DTV]-x(3)-[AGNSTV]-x(2)-[GILPV]-x(2)-[IL]
D 4: 12.1179 18(
16) M-x(3,5)-V-x-[ENR]-x-[ASTV]
E 5: 11.7492 16(
16) D-x(4,5)-N-x-[AGSTV]-[FILMV]
F 6: 7.8401 17(
16) V-x(2,3)-T
G 7: 7.8401 33(
16) L-x(2,3)-D
H 8: 7.8401 23(
16) S-x(0,1)-L
I 9: 7.8401 21(
16) S-x(1,2)-L
J 10: 7.3401 25(
16) D-x(1,3)-L
K 11: 7.3401 23(
16) L-x(1,3)-F
YD33_MYCTU, from Mycobacterium tuberculosis, "Hypothetical protein Rv1333".
You should obtain the sequence
>sw|Q10644|YD33_MYCTU Hypothetical protein Rv1333.
MNSITDVGGIRVGHYQRLDPDASLGAGWACGVTVVLPPPGTVGAVDCRGGAPGTRETDLL
DPANSVRFVDALLLAGGSAYGLAAADGVMRWLEEHRRGVAMDSGVVPIVPGAVIFDLPVG
GWNCRPTADFGYSACAAAGVDVAVGTVGVGVGARAGALKGGVGTASATLQSGVTVGVLAV
VNAAGNVVDPATGLPWMADLVGEFALRAPPAEQIAALAQLSSPLGAFNTPFNTTIGVIAC
DAALSPAACRRIAIAAHDGLARTIRPAHTPLDGDTVFALATGAVAVPPEAGVPAALSPET
QLVTAVGAAAADCLARAVLAGVLNAQPVAGIPTYRDMFPGAFGS
- How many domains does this protein have?
- Where are they?
- What are their functions? (CLick on each of them to access their individual entries)
- What can we say about the function of the protein?
- How many proteins do have the domain peptidase_S58?
Which other domains appear associated to the domain peptidase_S58? (Go to the Domain Organization box and click on "View Graphic")
Protein coded by the gene gcsf of Bos taurus (Granulocyte colony-stimulating factor precursor)
>sw|P35833|CSF3_BOVIN Granulocyte colony-stimulating factor precursor (G-CSF).
MKLMVLQLLLWHSALWTVHEATPLGPARSLPQSFLLKCLEQVRKIQADGAELQERLCAAH
KLCHPEELMLLRHSLGIPQAPLSSCSSQSLQLTSCLNQLHGGLFLYQGLLQALAGISPEL
APTLDTLQLDVTDFATNIWLQMEDLGAAPAVQPTQGAMPTFTSAFQRRAGGVLVASQLHR
FLELAYRGLRYLAEP
ICE9_HUMAN, from Homo Sapiens; precursor of caspase-9.
>ICE9_HUMAN
MDEADRRLLR RCRLRLVEEL QVDQLWDALL SRELFRPHMI EDIQRAGSGS RRDQARQLII
DLETRGSQAL PLFISCLEDT GQDMLASFLR TNRQAAKLSK PTLENLTPVV LRPEIRKPEV
LRPETPRPVD IGSGGFGDVG ALESLRGNAD LAYILSMEPC GHCLIINNVN FCRESGLRTR
TGSNIDCEKL RRRFSSLHFM VEVKGDLTAK KMVLALLELA QQDHGALDCC VVVILSHGCQ
ASHLQFPGAV YGTDGCPVSV EKIVNIFNGT SCPSLGGKPK LFFIQACGGE QKDHGFEVAS
TSPEDESPGS NPEPDATPFQ EGLRTFDQLD AISSLPTPSD IFVSYSTFPG FVSWRDPKSG
SWYVETLDDI FEQWAHSEDL QSLLLRVANA VSVKGIYKQM PGCFNFLRKK LFFKTS
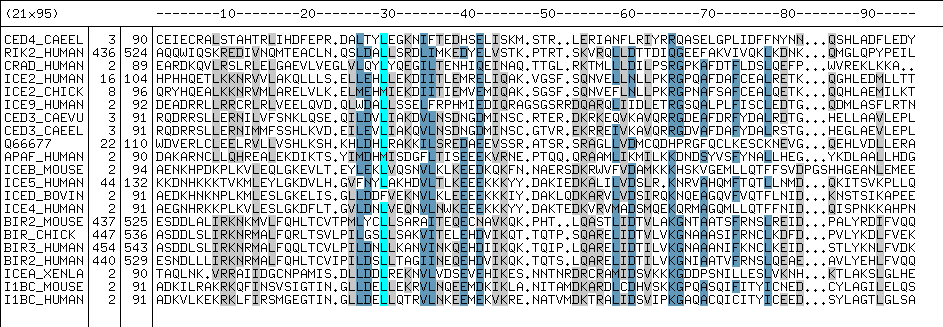
A piece of information that can be obtained from the PSMM file is the weight that has been defined for each sequence. More divergent sequences have larger weights.
Sequence Weights:
1 CED4_CAEEL/3-90 100
2 RIK2_HUMAN/436-524 94
3 CRAD_HUMAN/2-89 92
4 ICE2_HUMAN/16-104 54
5 ICE2_CHICK/8-96 62
6 ICE9_HUMAN/2-92 83
7 CED3_CAEVU/3-91 56
8 CED3_CAEEL/3-91 58
9 Q66677/22-110 89
10 APAF_HUMAN/2-90 96
11 ICEB_MOUSE/2-94 79
12 ICE5_HUMAN/44-132 69
13 ICED_BOVIN/2-91 62
14 ICE4_HUMAN/2-91 65
15 BIR2_MOUSE/437-525 58
...etc.
